
Tuesday, October 3, 2017
Server to server API calls Security
Calling Partner APIs from our application servers is a common use-case, a quick summary of options for securing such Server to server API calls
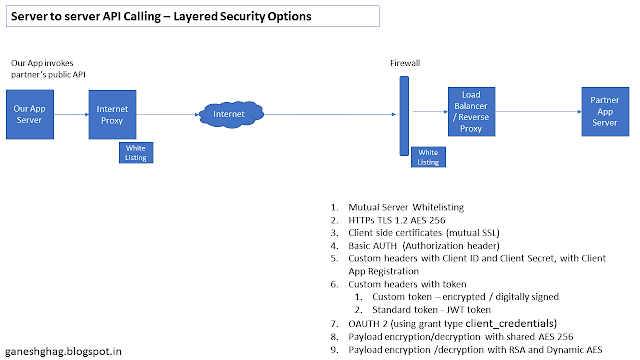
Sunday, August 13, 2017
Cloud, Elasticity and Microservices
Many enterprise customers are being seen talking about moving to the cloud and adopting microservices based architectures. This is especially seen in the Indian BFSI domain. Heres my two cents at how the things are evolving logically and trade offs that all BFSI Businesses should be aware of.
The incentive to move to the cloud
Conventional wisdom is slowly but surely tilting towards moving IT infrastructures to secure public clouds like AWS, Azure and IBM Bluemix. The reasons are many and varied and well established by now, I wont regurgitate the same here again. Irrespective of the particular reason for moving the newer enterprise applications to the cloud, it makes sense to ensure that the underlying applications can "leverage" the cloud based infrastructures to the fullest.
Elasticity is important
The cloud provides for dynamic provisioning of resources like processing power, storage, network bandwidth, etc. It then follows logically, that enterprise applications that are deployed on the cloud should be fully capable of "leveraging" this elasticity of the cloud to "scale out" over resources.
Most importantly since clouds are pay-as-you-go model, if the underlying architecture is able to "scale down" automatically, when customer demand is low, the cloud costs for running applications can be optimized. Such architectures which can optimize operating costs of the cloud are very desirable. Mind you, in the cloud, being able to "scale down" as per demand is not just a good-to-have but rather an imperative that has direct cost implications.
Enter Microservices
In a monolithic application based approach including app servers or ESBs or service orchestration containers, the size of the monolith restricts the extent to which the scale-down can occur. Hence the architectural approach of microservices which are much more granular lends itself to better scale down capabilities, along with various important technical advantages of microservices
Containerization and choices
OK so microservices lend themselves well to cloud deployments, due to their granularity! But managing microservices, monitoring them, ensuring fault tolerance, reliability, scalability, is now a challenging task. Using light weight and proven container technologies like docker becomes inevitable. Docker also provides the much needed portability.
But managing the containers can itself become a complex task. Using a container management tool like docker swarm is good for less complex deployments and if you need to a single out of the box solution for container management. For more complex enterprise wide deployments a open source and portable and pluggable docker management framework like kubernetes is much more practical.
For a quick compare between swarm and kubernetes
In addition, the docker container will need some deep integrations with your cloud provider, remember all this is running on the cloud ;-)
Here too, we have cloud provider based solutions like EC2's Container service which can be considered to be alternatives to kubernetes. But be aware that choosing a cloud provider based container management solution will mean no portability and vendor lock-in with your cloud provider
The architectural shift to microservices, is just the tip of the ice berg when considering your move to the cloud. In subsequent articles I will be talking about other aspects of your move to the cloud, which will affect the way your enterprise applications interact with the world. Some topics I intend to cover are Security and using API Gateways for integrations.
The incentive to move to the cloud
Conventional wisdom is slowly but surely tilting towards moving IT infrastructures to secure public clouds like AWS, Azure and IBM Bluemix. The reasons are many and varied and well established by now, I wont regurgitate the same here again. Irrespective of the particular reason for moving the newer enterprise applications to the cloud, it makes sense to ensure that the underlying applications can "leverage" the cloud based infrastructures to the fullest.
Elasticity is important
The cloud provides for dynamic provisioning of resources like processing power, storage, network bandwidth, etc. It then follows logically, that enterprise applications that are deployed on the cloud should be fully capable of "leveraging" this elasticity of the cloud to "scale out" over resources.
Most importantly since clouds are pay-as-you-go model, if the underlying architecture is able to "scale down" automatically, when customer demand is low, the cloud costs for running applications can be optimized. Such architectures which can optimize operating costs of the cloud are very desirable. Mind you, in the cloud, being able to "scale down" as per demand is not just a good-to-have but rather an imperative that has direct cost implications.
Enter Microservices
In a monolithic application based approach including app servers or ESBs or service orchestration containers, the size of the monolith restricts the extent to which the scale-down can occur. Hence the architectural approach of microservices which are much more granular lends itself to better scale down capabilities, along with various important technical advantages of microservices
Containerization and choices
OK so microservices lend themselves well to cloud deployments, due to their granularity! But managing microservices, monitoring them, ensuring fault tolerance, reliability, scalability, is now a challenging task. Using light weight and proven container technologies like docker becomes inevitable. Docker also provides the much needed portability.
But managing the containers can itself become a complex task. Using a container management tool like docker swarm is good for less complex deployments and if you need to a single out of the box solution for container management. For more complex enterprise wide deployments a open source and portable and pluggable docker management framework like kubernetes is much more practical.
For a quick compare between swarm and kubernetes
In addition, the docker container will need some deep integrations with your cloud provider, remember all this is running on the cloud ;-)
Here too, we have cloud provider based solutions like EC2's Container service which can be considered to be alternatives to kubernetes. But be aware that choosing a cloud provider based container management solution will mean no portability and vendor lock-in with your cloud provider
The architectural shift to microservices, is just the tip of the ice berg when considering your move to the cloud. In subsequent articles I will be talking about other aspects of your move to the cloud, which will affect the way your enterprise applications interact with the world. Some topics I intend to cover are Security and using API Gateways for integrations.
Sunday, June 11, 2017
Spark Quick Review : Study Notes
The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.
Driver program's in memory array can be converted to distributed data structure using parallelize
Spark can create distributed datasets from any storage source supported by Hadoop, including your local file system, HDFS, Cassandra, HBase, Amazon S3, etc.
RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset.
For example, map is a transformation that passes each dataset element through a function and returns a new RDD representing the results. On the other hand, reduce is an action that aggregates all the elements of the RDD using some function and returns the final result to the driver program (although there is also a parallel reduceByKey that returns a distributed dataset).
Since RDDs are distributed data stuctures, something special needs to be done to count elements inside RDD.
// Wrong: Don't do this!!
rdd.foreach(x -> counter += x);
Total Character Count Example
The following code uses the reduceByKey operation on key-value pairs to count how many times each line of text occurs in a file:
Filter lines in a file for occurence of string "ganesh"
JavaRDD<String> logData = sc.textFile(logFile).cache();
JavaRDD<String> retData = logData.filter(s -> s.contains("ganesh"));
Different types of transformations and actions
https://spark.apache.org/docs/2.1.0/programming-guide.html
Word Count
JavaRDD<String> words = lines.flatMap(s->Arrays.asList(s.split(" ")).iterator()); JavaPairRDD<String, Integer> pairs = words.mapToPair(s -> new Tuple2(s, 1)); JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b);
Shared Variables
Driver program's in memory array can be converted to distributed data structure using parallelize
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);Spark can create distributed datasets from any storage source supported by Hadoop, including your local file system, HDFS, Cassandra, HBase, Amazon S3, etc.
JavaRDD<String> distFile = sc.textFile("data.txt");RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset.
For example, map is a transformation that passes each dataset element through a function and returns a new RDD representing the results. On the other hand, reduce is an action that aggregates all the elements of the RDD using some function and returns the final result to the driver program (although there is also a parallel reduceByKey that returns a distributed dataset).
Since RDDs are distributed data stuctures, something special needs to be done to count elements inside RDD.
// Wrong: Don't do this!!
rdd.foreach(x -> counter += x);
rdd.collect().foreach(println) //can give out of memory since all data brought to drivernode
rdd.take(100).foreach(println)Total Character Count Example
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);The following code uses the reduceByKey operation on key-value pairs to count how many times each line of text occurs in a file:
JavaRDD<String> lines = sc.textFile("data.txt");
JavaPairRDD<String, Integer> pairs = lines.mapToPair(s -> new Tuple2(s, 1));
JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b);Filter lines in a file for occurence of string "ganesh"
JavaRDD<String> logData = sc.textFile(logFile).cache();
JavaRDD<String> retData = logData.filter(s -> s.contains("ganesh"));
Different types of transformations and actions
https://spark.apache.org/docs/2.1.0/programming-guide.html
Word Count
JavaRDD<String> words = lines.flatMap(s->Arrays.asList(s.split(" ")).iterator()); JavaPairRDD<String, Integer> pairs = words.mapToPair(s -> new Tuple2(s, 1)); JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b);
Shared Variables
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3});
broadcastVar.value();
// returns [1, 2, 3]LongAccumulator accum = jsc.sc().longAccumulator();
sc.parallelize(Arrays.asList(1, 2, 3, 4)).foreach(x -> accum.add(x));
// ...
// 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
accum.value();
// returns 10
Subscribe to:
Posts (Atom)